
Artificial Intelligence
Copper Horse has been at the forefront of adversarial AI research. Having participated on multiple research projects from working on embedded analytics to protect connected vehicle ECUs, assessing the current mobile network landscape and the impact of AI attacks, through to our most recent collaborative AI project working on security and AI models for a Trustable AI Bill of Materials (TAIBOM). Whatever your AI cyber security needs, Copper Horse are here for you. We specialise in far-future and complex challenges cyber security. If you would like to discuss how we can help, please reach out using the contact form here.
Case Study – TAIBOM AI Models and Adversarial Attacks
The TAIBOM initiative – funded by the UKRI Technology Missions Fund – has once again put Copper Horse at the forefront of the global trust and security landscape. This project strengthened our existing partnerships with NquiringMinds Ltd and the University of Oxford, while also contributing to industry initiatives as a member of the TechWorks-AI industry community.
The AI Models
As part of this research project, Copper Horse staff developed two AI models to test the resilience of TAIBOM attestations against external attacks. The security testing of the AI models covered many different attack vectors across a range of diverse threats, resulting in attacks using adversarial input manipulation, data poisoning, model theft and leakage together with integrity compromise. Thirty high-risk scenarios (fifteen for each AI model) were selected and resilience tests on the models were executed to demonstrate the fundamental importance and value of AI developers and implementers using TAIBOM trustworthiness attestations to create verifiable claims against AI components with the goal of preventing potential threats faced in the real world from bad actors.
The two AI models focused on two very different use cases: the detection of tampered and legitimate speed limit signs, with the second use case focusing on the translation of early modern shorthand or ‘short writing’ as it is also known. Both implementations revealed a strong potential for useful real-world applications and future commercialisation.
Use Case 1: Traffic Sign Defacement Recognition

Image 1 – The Copper Horse automotive hacking rig
The AI model is trained and designed to detect and classify speed limit road signs in real time, using a live feed through the inference interface which can determine whether signs have either been tampered with, or classifying and displaying the corresponding speed limit whilst a vehicle is in motion.
Drilling into more detail on the road sign detection use case, the AI system consists of an object detection model, for which a YOLO pre-trained model is employed and fine-tuned to detect speed limit like object shapes, and a two Convolutional Neural Networks (CNNs) for the classification of tampered vs authentic signs, and of the actual value of the speed limit. The CNNs have been improved employing Inception Layers, following the GoogLeNet architecture.
The model has been trained using data collected using an in-house developed vehicle hacking simulator running Euro Truck simulator 2 with the ProMods modification which provides much more realistic roads (see Image 1). On top of this, Copper Horse ‘modded the mod’ to add in custom signage and elements to exercise the AI model. The simulator offers a realistic and highly customisable environment and allows users to experience pre-created hacked car driving scenarios whilst also seeing the road sign tamper detection model deliver results in real time.
The vehicle hacking simulator platform consists of a triple monitor setup linked together as one display with an additional display which mirrors the centre monitor. The additional display is then routed into a capture card, which converts the signal to a webcam input. A second computer receives the video input into OBS, and outputs it as a virtual camera which we can use as a local input.
A secondary “sign capture tool” has also been developed to speed up the data collection, leveraging the detection model to passively gather training data as the vehicle is driven in the simulator (see Image 2). This tool offers significant efficiency improvements allowing us to live capture training data rather than capturing manually.

Image 2 – Automated training data collection system capturing the speed signs
The highly realistic data collected in the simulator, which also includes variations in lighting and weather conditions, has been used to train the AI model. When tested on real-world scenarios using video recorded with a dash cam, the model demonstrated high classification performance with the inferencing (see Image 3). This success further confirms the potential of using digital twins to effectively train AI systems.
The heart of the use case for this AI solution was to detect defaced road signs – it could for example be integrated alongside an existing Advanced Driver Assistance Systems (ADAS), to provide an additional level of assurance to vehicular systems that start to rely on this type of information as cars move towards higher levels of autonomy. Defaced signs have become particularly common in Wales, where the contentious introduction of blanket 20mph limits led to a backlash which saw defacement of many of the signs with spray paint and stickers.
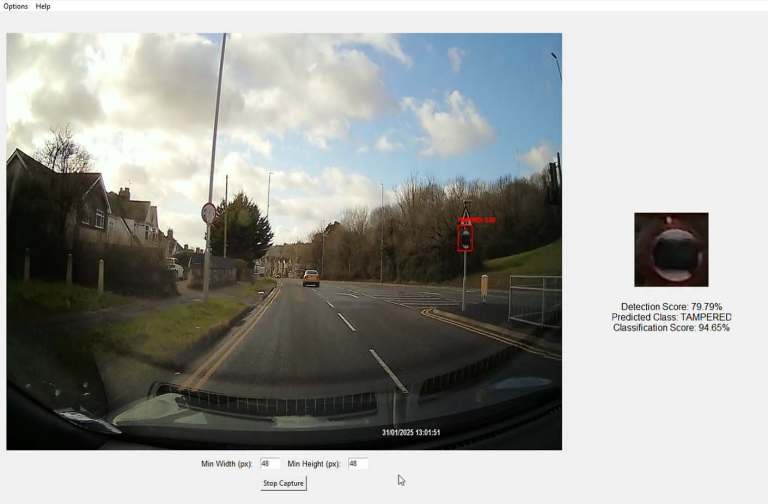
Image 3 – Inference on dashcam footage
In Copper Horse’s case, both of the AI models described here were developed as ‘toy models’ – essentially to prove out AI Bills of Materials functionally, but also from a security point of view. Copper Horse went on to create multiple realistic threat scenarios which were then used as part of adversarial abuse to different part parts of the AI system – whether it be the datasets, model weights or inferencing engine.
Use Case 2: Paleography – Early Modern Short-Writing

Image 4 Copper Horse’s short writing AI tool demonstrated at Bletchley Park
The second use case AI system is designed to recognise text written in early-modern short-writing (or shorthand). It is designed for processing historical documents, and it currently implements a large set of words pertaining to Thomas Shelton’s 1647 ‘Tachygraphy’ system, used most notably by Samuel Pepys.
A custom dataset consisting of 64 symbols with 100 variants of each symbol was created to train the model. The dictionary has been coded using a universal character ID system which make it significantly easier to catalogue the ongoing expansion of the dataset, as well as to allow support for other shorthand formats such as logographic / pictographic writing systems such as Egyptian Hieroglyphics or Minoan Linear B. The initial goal is to provide a useful tool for researchers to assist in the deciphering of early modern shorthand texts, of which there are many thousands of pages and much of which hasn’t been read for hundreds of years.
The AI system uses a custom CNN model that follows the GoogLeNet architecture which is capable of recognising and translating individual shorthand characters. First the images are pre-processed, edge detection is performed using Scharr operator and Otsu thresholding to isolate the key features of each character. The images are then centred, padded and translated down to a consistent size of 64×64 pixels. To further increase the number of images for training data and better reflect the variations in handwriting, the characters go through data augmentation, a technique which applies a gradual random zoom and scaling to create more variations from the existing dataset. The model takes 64×64 greyscale images as an input to a standard convolutional layer, followed by maxpooling to extract low-level features. It then passes through a series of custom convolutional filters (1×1, 3×3, 5×5) and pooling operations in parallel, combining their outputs to capture rich, multi-scale features. After the feature extraction process, the output is flattened and fed through two fully connected layers with drop out for regularisation, followed by a softmax output layer for multiclass classification. During the training process, the model uses a Sparse Categorical Cross Entropy loss function, which is particularly suited to integer-based classification tasks. We also deploy the Adam optimiser for efficient gradient based optimisation and utilise Early Stopping and Reduce LR On Plateau to prevent overfitting and improve model performance respectively.
The inferencing script provides a user-friendly interface which allows the manual selection the individual, sometimes composite, symbols to be processed. While the inferencing engine displays the best translation, the interface allows the user to visualise the top scored predictions and to select the opportune translations of individual symbols that may have been misclassified by the model. A demonstration of the tool in action was shown at the TechWorks Engineering Trustworthy AI conference at Bletchley Park (see Image 4).
The AI has been successfully employed as a demonstration to decipher text in Thomas Shelton’s Lord’s Prayer from 1647 and also the Shelton version of the Lord’s Prayer from Folger MS V.b.110 (see this blog from Heather Wolfe for more details (noting the error in that blog which states 1674 – it should be 1647). The dictionary is growing and has been validated against other self-generated shorthand texts.
The Lord’s Prayer, the Articles of the Creed and the Ten Commandments were commonly used in shorthand manuals of the time to assist readers in understanding the writing system.
Images 5 and 6 here demonstrate the tool in use.

Image 5 – Part of the deciphered, hand-written copy of an early modern version of the Lord’s Prayer

Image 6 – Part of the Shelton’s Lord’s Prayer from Folger MS V.b.110 deciphered.